How to integrate Jira and Google Drive to archive Jira issue attachments
Jira and file attachments
Jira allows you to upload file attachments and link them to an issue. In addition, you can also copy and paste file attachments into the description field and into comments. These become attachments in the issue but you also get a preview of the attachment inside the description or comment. This is very useful for image attachments since you can see the entire image without having to click on anything, like in the example below.
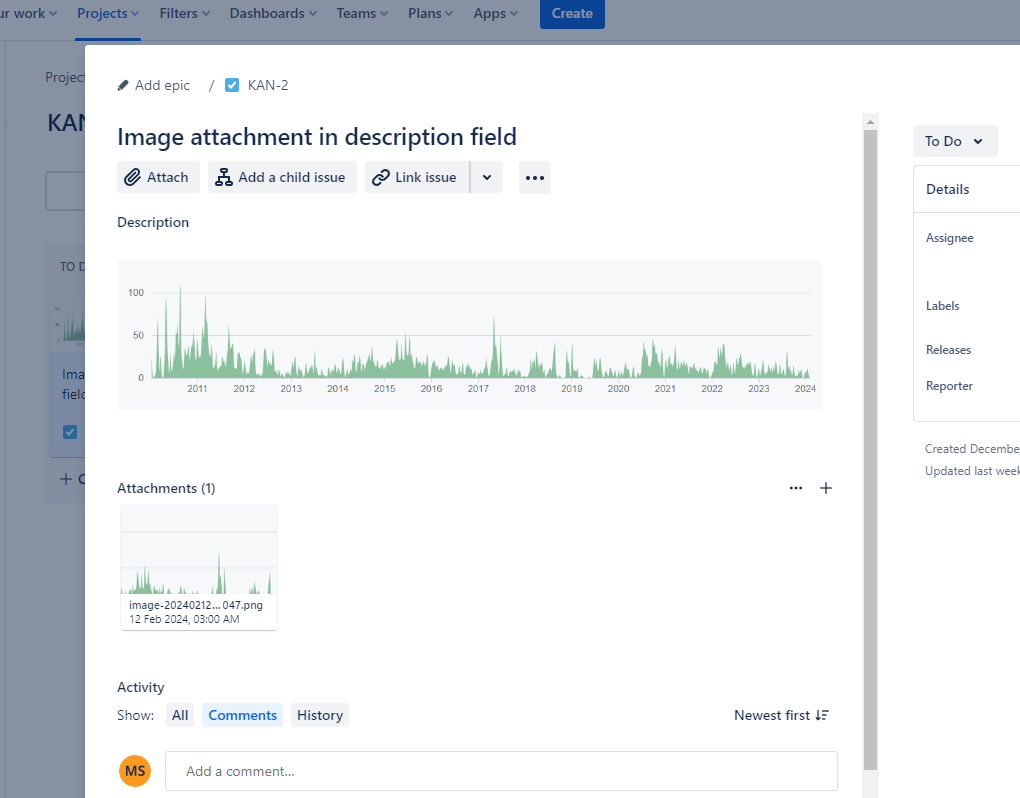
For many years, there were problems when an issue accumulated too many attachments. Anything related to attachments just stopped working. There is a full history listed here: https://jira.atlassian.com/browse/JRACLOUD-74515
As per that page, in July 2021, Atlassian were saying that they would not support more than 120 attachments. This understandably led to many user complaints.
Eventually, in June 2023, Atlassian relented, and they released an update saying that the normal default attachment functionality would work up till the issue had over 150 attachments. After that the issue would only display attachments in the list view. Users can still view attachments, upload new attachments, download attachments and delete attachments. However, the attachment preview inside the description field and comment field would no longer work.
What this means is that to get back the attachment preview, you need to reduce the number of attachments inside the issue to below 150. You can delete old ones but what if you need to keep all the attachments? This is the problem that we were trying to solve. We decided to build a script that allowed us to archive all existing attachments to Google Drive. This way newer attachments that are added afterwards can keep their preview functionality, no matter how many attachments have been added to the issue in the past.
Apart from this requirement to preview attachments, you might need to archive your attachments because of space limitations on your Jira plan. Here is someone complaining about exactly that:
This same script that we have built lets you archive your attachments so that they do not use up storage space in your Jira account.
We found someone wanting to do something similar to this but wanting to do it using JQL and an Automation Rule to send a Web Request.
https://community.atlassian.com/t5/Jira-Software-questions/Integration-with-Google-Drive/qaq-p/2341316
We decided to do it differently. We wanted to build something outside of both Jira and Google Drive, that connects to Jira, finds all attachments, uploads the attachments to Google Drive and then replaces the attachments in Jira with links to Google Drive. That way users can still click on a link to see the image.
Let’s go through the process of how we set this up, step-by-step, so that you can do the same.
Step 1: Set up a Node.js project
This integration, like all our integrations, is coded in Node.js. We need to create a folder structure for the integration like this:
.
├── .env
├── .env.example
├── downloads
│ └── image.png
├── google-service-account-key.json
├── package-lock.json
├── package.json
└── src
├── googleDriveClient.js
├── index.js
└── jiraClient.js
.env will contain environment variables (API keys and config settings)
/downloads will be the folder where attachments are downloaded to temporarily.
google-service-account-key.json will be a JSON file containing auth credentials to connect to Google Drive.
/src/index.js will be the the main script.
/src/googleDriveClient.js will contain all the code that connects to Google Drive.
/src/jiraClient.js will contain all the code that connects to Jira.
This is what the .env file will contain:
LOG_LEVEL=debug
PORT=3000
JIRA_DOMAIN=xxxxx.atlassian.net
JIRA_EMAIL=xxxxx@gmail.com
JIRA_API_TOKEN=XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX
GOOGLE_DRIVE_FOLDER_NAME=jira2gdrive
GOOGLE_ACCOUNTS_WITH_READ_ACCESS=xxxxxxxxxx@gmail.com,yyyyyyyyyyyy@gmail.com
GOOGLE_ACCOUNTS_WITH_WRITE_ACCESS=xxxxxxxxxxxx@gmail.com,yyyyyyyyyyyy@gmail.com
The Jira config settings will come in the next step. For now, you can add what you want the Google Drive folder name to be. This will be the folder under which all the attachments will be uploaded to. Also fill in the users who need read / write access to this folder.
Step 2: Create a Jira API key
Follow these instructions to create API keys for Jira: How to create API keys for Jira.
Then paste the the Jira domain, the Jira login email address and Jira API token to the .env file into these variables
JIRA_DOMAIN=xxxxx.atlassian.net
JIRA_EMAIL=xxxxx@gmail.com
JIRA_API_TOKEN=XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX
Step 3: Create a Google service account
We cannot use a normal Google API key since those API keys do not have access to Google Drive resources. We need to create and use a Google service account. A service account is a special kind of Google account used by an app, rather than a person, to authenticate and access Google APIs.
Follow these instructions to create the Google service account: How to create a Google service account
At the end of that process you will download a JSON file containing the auth credentials. Save this file to the root folder to a file called
google-service-account-key.json
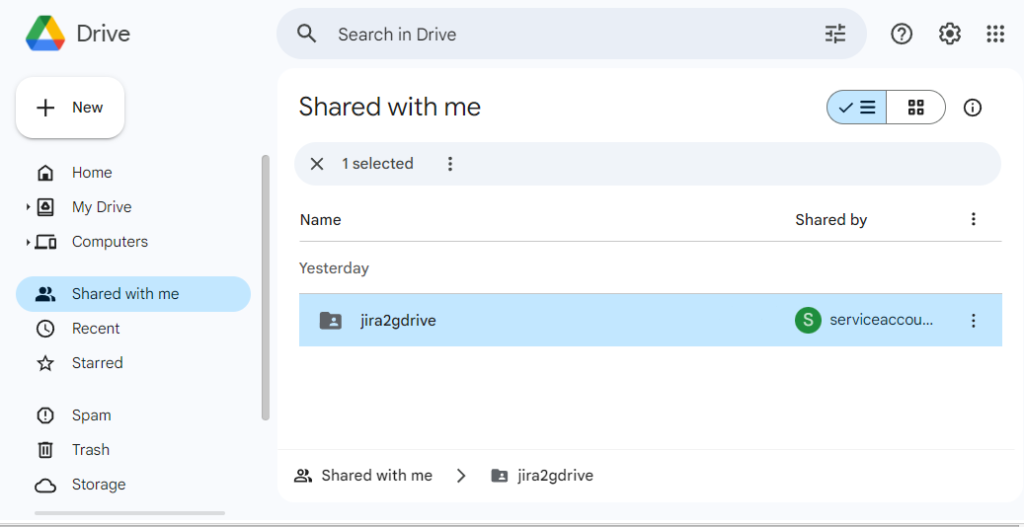
The service account will have its own Google Drive folder. When it uploads the attachments there those attachments will not be visible to us and our users. In our script we will have code that will share the files with us and all our users. Now we can see the files under ‘Shared with me’.
Step 4: Enable the Google Drive API
Follow these instructions to enable the Google Drive API so that we can access and upload files to Google Drive using our code: How to enable the Google Drive API.
Step 5: Server setup
You can use any existing Linux or Windows server to run this script. We decided to get a new cloud VM (virtual machine) for the script. It was a VM with shared vCPU since the script only runs periodically and does not need constant compute power. So the cost was only a few dollars a month.
Log into the Linux server.
Create a new user account where all the code will run.
# adduser jira2gdrive
Change to the archiver user:
# su - jira2gdrive
Install node via nvm (for the archiver user)
$ curl -o- https://raw.githubusercontent.com/nvm-sh/nvm/v0.39.5/install.sh | bash
$ source ~/.bashrc
$ nvm install node
$ node -v
Step 6: Node modules
We can create a package.json file that contains the project name and a list of all the node modules that we are using.
{
"name": "jira2gdrive",
"version": "1.0.0",
"description": "",
"main": "src/index.js",
"scripts": {
"start": "node src/index.js",
"test": "echo \"Error: no test specified\" && exit 1"
},
"author": "",
"license": "ISC",
"dependencies": {
"axios": "^1.6.7",
"dotenv": "^16.4.1",
"googleapis": "^131.0.0"
}
}
To install the modules we run:
$ npm install
Step 7: The Jira client
We need to write the code for the Jira client that will connect to the Jira API. This client needs to fetch project details, fetch issues, fetch attachments, update issue descriptions, update issue comments and delete attachments.
The code goes into this file: /src/jiraClient.js
Here is the full code for the client:
const axios = require('axios');
const fs = require('fs');
const fsp = fs.promises;
const path = require('path');
/**
* Represents a client for interacting with Jira's REST API, providing functionality
* to perform operations like fetching project details, managing issues, and more.
*
* This client uses basic authentication with an email and API token to access
* Jira's REST API.
*/
class JiraClient {
/**
* Initializes a new instance of the JiraClient class with the necessary
* authentication details to interact with the Jira REST API.
*
* @param {string} domain - The domain of the Jira instance to connect to, e.g., 'yourcompany.atlassian.net'.
* @param {string} email - The email address associated with the Jira account.
* @param {string} token - The API token generated from the Jira account settings.
*/
constructor(domain, email, token) {
this.domain = domain;
this.email = email;
this.token = token;
this.authHeader = {
'Authorization': `Basic ${Buffer.from(`${this.email}:${this.token}`).toString('base64')}`,
'Accept': 'application/json'
};
}
/**
* Fetches all projects from the Jira instance.
*
* @returns {Promise<Object[]>} A promise that resolves with an array of project objects fetched from Jira.
* @throws {Error} Throws an error if the request to fetch projects fails.
*/
async getAllProjects() {
try {
const response = await axios.get(`https://${this.domain}/rest/api/3/project`, {
headers: this.authHeader
});
return response.data;
} catch (error) {
console.error('Error fetching projects:', error);
throw error;
}
}
/**
* Fetches all issues within a specified project from Jira. Optionally filters issues based on attachment presence,
* how recently they've been updated, and whether to return only IDs and keys.
*
* @param {string} projectId - The ID of the project from which to fetch issues.
* @param {boolean} [mustHaveAttachments=true] - Whether to only include issues that have attachments. Defaults to true.
* @param {number} [updatedWithinDays=1] - The number of days within which issues must have been updated to be included. Defaults to 1.
* @param {boolean} [idsOnly=true] - Whether to return only the IDs and keys of the issues, not full details. Defaults to true.
* @returns {Promise<Object[]>} A promise that resolves with an array of issue objects (or issue IDs and keys if `idsOnly` is true) fetched from Jira.
* @throws {Error} Throws an error if the request to fetch issues fails.
*/
async getAllIssuesInProject(projectId, mustHaveAttachments = true, updatedWithinDays = 1, idsOnly = true) {
try {
const jql = `project=${projectId}${mustHaveAttachments ? ' AND attachments is not EMPTY' : ''} AND updated > -${updatedWithinDays}d ORDER BY updated ASC`;
let fields = '';
if (idsOnly) {
fields = 'id,key';
}
const response = await axios.get(`https://${this.domain}/rest/api/3/search?jql=${encodeURIComponent(jql)}&fields=${fields}`, {
headers: this.authHeader
});
return response.data.issues;
} catch (error) {
console.error(`Error fetching issues for project ${projectId}:`, error);
throw error;
}
}
/**
* Fetches detailed information for a specific issue from Jira using the issue's ID or key.
*
* @param {string} issueIdOrKey - The ID or key of the issue for which to fetch details (e.g., "PROJECT-123").
* @returns {Promise<Object>} A promise that resolves with the detailed information of the requested issue from Jira.
* @throws {Error} Throws an error if fetching the issue details fails.
*/
async getIssueDetails(issueIdOrKey) {
try {
const response = await axios.get(`https://${this.domain}/rest/api/3/issue/${issueIdOrKey}`, {
headers: this.authHeader
});
return response.data;
} catch (error) {
console.error(`Error fetching details for issue ${issueIdOrKey}:`, error);
throw error;
}
}
/**
* Downloads an attachment from Jira and saves it to a local directory.
*
* @param {Object} attachment - The attachment object containing the necessary data for downloading.
* @param {string} attachment.content - The URL to the content of the attachment.
* @param {string} attachment.filename - The name of the file to be saved as.
* @returns {Promise<{attachmentFileId: string, filePath: string}>} A promise that resolves with an object containing the UUID (attachmentFileId) of the downloaded file and the local file path (filePath) where the file has been saved.
* @throws {Error} Throws an error if the download or any other operation fails.
*/
async downloadAttachment(attachment) {
try {
// Make an initial request to get the redirect URL without following the redirect. We need to do this to get the attachment ID (the UUID)
const initialResponse = await axios.get(attachment.content, {
headers: this.authHeader,
maxRedirects: 0, // Prevent axios from following redirects
validateStatus: function (status) {
return status >= 200 && status < 400; // Accept all 2xx and 3xx responses
}
});
// Extract the UUID from the redirect URL in the 'location' header
const locationHeader = initialResponse.headers.location;
const uuidMatch = locationHeader && locationHeader.match(/file\/([a-f\d-]+)\/binary/);
if (!uuidMatch) {
throw new Error('UUID not found in the redirect URL.');
}
const uuid = uuidMatch[1];
// Proceed to download the file using the redirect URL
const response = await axios.get(locationHeader, {
headers: this.authHeader,
responseType: 'stream'
});
const downloadsDir = path.resolve(__dirname, '..', 'downloads');
try {
await fsp.access(downloadsDir);
} catch {
await fsp.mkdir(downloadsDir);
}
const filePath = path.join(downloadsDir, attachment.filename);
const writer = fs.createWriteStream(filePath);
response.data.pipe(writer);
return new Promise((resolve, reject) => {
writer.on('finish', () => resolve({ attachmentFileId: uuid, filePath: filePath }));
writer.on('error', reject);
});
} catch (error) {
console.error(`Error downloading attachment ${attachment.filename}:`, error);
throw error;
}
}
/**
* Deletes a specified attachment from Jira.
*
* @param {string} attachmentId - The unique identifier of the attachment to be deleted.
* @returns {Promise<Object>} A promise that resolves with the API response data upon successful deletion.
* @throws {Error} Throws an error if the deletion fails, including details from the API response.
*/
async deleteAttachment(attachmentId) {
console.log(`Deleting attachment ${attachmentId}...`);
try {
const response = await axios.delete(`https://${this.domain}/rest/api/3/attachment/${attachmentId}`, {
headers: this.authHeader
});
console.log(`Attachment ${attachmentId} deleted successfully.`);
return response.data;
} catch (error) {
console.error(`Error deleting attachment ${attachmentId}:`, error);
throw error;
}
}
/**
* Replaces an attachment referenced in an Atlassian Document Format (ADF) node with a hyperlink.
*
* This function searches for a media node within the provided ADF node that matches the specified
* attachment file ID. If found, it replaces the media node with a paragraph node containing a text
* link to the replacement URL. The function operates recursively on any child nodes.
*
* @param {Object} node - The ADF node to be processed. This can be any part of an ADF document structure.
* @param {string} attachmentFileId - The file ID of the attachment to be replaced. This ID is used to
* identify the relevant media node within the ADF structure.
* @param {string} attachmentFileName - The display name of the attachment. This is used as the text for the
* hyperlink that replaces the media node.
* @param {string} replacementUrl - The URL of the replacement resource. This URL is used as the href for the
* hyperlink that replaces the media node.
* @returns {Object} The modified ADF node with the specified attachment replaced by a hyperlink. If the
* specified attachment is not found, the original node is returned unchanged.
*/
replaceAttachmentInADF(node, attachmentFileId, attachmentFileName, replacementUrl) {
// If it's a 'mediaSingle' node, check its contained 'media' nodes
if (node.type === 'mediaSingle') {
// We assume each 'mediaSingle' contains one 'media' node in its content array
const mediaNode = node.content.find(n => n.type === 'media');
// Check if the 'media' node's ID matches our target attachment ID
if (mediaNode && mediaNode.attrs.id === attachmentFileId) {
// Replace with a paragraph containing the link to the Google Drive attachment
return {
type: 'paragraph',
content: [{
type: 'text',
text: attachmentFileName,
marks: [{
type: 'link',
attrs: {
href: replacementUrl,
title: attachmentFileName
}
}]
}]
};
}
}
// Recursively process any children nodes
if (node.content && Array.isArray(node.content)) {
return {
...node,
content: node.content.map(childNode => this.replaceAttachmentInADF(childNode, attachmentFileId, attachmentFileName, replacementUrl))
};
}
return node;
}
/**
* Updates the description of a Jira issue with the provided text.
*
* @param {string} issueId - The ID or key of the issue whose description is to be updated.
* @param {Object} updatedDescriptionAdf - The new description for the issue in Atlassian Document Format (ADF),
* which allows for rich text formatting. The object must have a `type`
* of 'doc', a `version`, and a `content` array as per ADF specification.
* @returns {Promise<Object>} A promise that resolves with the updated issue data from Jira.
* @throws {Error} Throws an error if the update operation fails, including the error response from the API.
*/
async updateIssueDescription(issueId, updatedDescriptionAdf) {
try {
const response = await axios.put(`https://${this.domain}/rest/api/3/issue/${issueId}`, {
fields: {
description: updatedDescriptionAdf
}
}, {
headers: this.authHeader
});
return response.data;
} catch (error) {
console.error(`Error updating description for issue ${issueId}:`, error);
throw error;
}
}
/**
* Updates a specific comment within a Jira issue using the provided content.
*
* @param {string} issueId - The ID or key of the issue that contains the comment to be updated.
* @param {string} commentId - The unique identifier of the comment to update.
* @param {Object} updatedCommentAdf - The new content for the comment in Atlassian Document Format (ADF),
* allowing for rich text formatting. This object should conform to the
* ADF specification with a `type` of 'doc', a `version`, and a `content`
* array.
* @returns {Promise<Object>} A promise that resolves with the API response containing the updated comment data from Jira.
* @throws {Error} Throws an error if the update operation fails, including details from the API response.
*/
async updateComment(issueId, commentId, updatedCommentAdf) {
try {
const response = await axios.put(`https://${this.domain}/rest/api/3/issue/${issueId}/comment/${commentId}`, {
body: updatedCommentAdf
}, {
headers: this.authHeader
});
return response.data;
} catch (error) {
console.error(`Error updating comment ${commentId} for issue ${issueId}:`, error);
throw error;
}
}
/**
* Creates a new text comment on a specified Jira issue.
*
* @param {string} issueId - The ID or key of the issue to which the comment will be added.
* @param {string} commentText - The plain text content of the comment to be created.
* @returns {Promise<Object>} A promise that resolves with the API response containing the data of the newly created comment.
* @throws {Error} Throws an error if the request to create the comment fails, including details from the API response.
*/
async createTextComment(issueId, commentText) {
try {
const response = await axios.post(`https://${this.domain}/rest/api/3/issue/${issueId}/comment`, {
body: {
type: "doc",
version: 1,
content: [
{
type: "paragraph",
content: [
{
type: "text",
text: commentText
}
]
}
]
}
}, {
headers: this.authHeader
});
return response.data;
} catch (error) {
console.error(`Error creating comment for issue ${issueId}:`, error);
throw error;
}
}
/**
* Creates a new comment on a specified Jira issue using Atlassian Document Format (ADF) content.
*
* @param {string} issueId - The ID or key of the issue to which the comment will be added.
* @param {Object} adfContent - The content of the comment formatted in Atlassian Document Format (ADF).
* This object should conform to the ADF specification, including a `type` of 'doc',
* a `version`, and a `content` array detailing the structured content of the comment.
* @returns {Promise<Object>} A promise that resolves with the API response containing the data of the newly created comment.
* @throws {Error} Throws an error if the request to create the comment fails, providing details from the API response for troubleshooting.
*/
async createAdfComment(issueId, adfContent) {
try {
const response = await axios.post(`https://${this.domain}/rest/api/3/issue/${issueId}/comment`, {
body: adfContent
}, {
headers: this.authHeader
});
console.log(`Comment created successfully for issue ${issueId}.`);
return response.data;
} catch (error) {
console.error(`Error creating comment for issue ${issueId}:`, error);
throw error;
}
}
}
// Export as a singleton
module.exports = JiraClient;
Step 8: The Google Drive client
We need the code for the Google Drive client that will connect to the Google Drive API. It needs to create folders in Google Drive, upload files to those Google Drive folders, and change permissions for those files and folders.
The code goes into this file: /src/googleDriveClient.js
Here is the full code for the client:
const { google } = require('googleapis');
const path = require('path');
const fs = require('fs');
/**
* Represents a client for interacting with Google Drive, providing functionaly
* to upload files, manage permissions, and handle Google Drive operations.
*
* This client utilizes a service account for authentication, allowing automated
* access to Google Drive APIs
*
*/
class GoogleDriveClient {
/**
* Creates an instance of the class responsible for interacting with Google Drive.
*
* @param {string} serviceAccountKeyFile - The path to the service account key file.
* @param {string[]} googleAccountsWithReadAccess - An array of email addresses to grant read access to.
* @param {string[]} googleAccountsWithWriteAccess - An array of email addresses to grant write access to.
*/
constructor(serviceAccountKeyFile, googleAccountsWithReadAccess, googleAccountsWithWriteAccess) {
this.serviceAccountKeyFile = serviceAccountKeyFile;
this.googleAccountsWithReadAccess = googleAccountsWithReadAccess;
this.googleAccountsWithWriteAccess = googleAccountsWithWriteAccess;
this.drive = null;
this.initializeDriveClient();
}
/**
* Initializes the Google Drive client with the necessary authentication.
* This method sets up the `drive` property of the class instance for further API calls.
*/
initializeDriveClient() {
const auth = new google.auth.GoogleAuth({
keyFile: this.serviceAccountKeyFile,
scopes: ['https://www.googleapis.com/auth/drive'],
});
this.drive = google.drive({ version: 'v3', auth });
}
/**
* Uploads a file to Google Drive and returns its ID.
*
* @param {string} folderId - The ID of the Google Drive folder where the file will be uploaded.
* @param {string} localFilePath - The local file system path of the file to upload.
* @returns {Promise<string>} A promise that, when resolved, returns the ID of the uploaded file on Google Drive.
*/
async uploadFile(folderId, localFilePath) {
const fileMetadata = {
name: path.basename(localFilePath),
parents: [folderId]
};
const media = {
mimeType: 'application/octet-stream', // Replace with the correct MIME type if known
body: fs.createReadStream(localFilePath),
};
try {
const response = await this.drive.files.create({
resource: fileMetadata,
media: media,
fields: 'id'
});
return response.data.id;
} catch (error) {
console.error('Error uploading file to Google Drive:', error);
throw error;
}
}
/**
* Finds or creates a folder on Google Drive and returns its ID.
*
* @param {string} folderName - The name of the folder to find or create.
* @param {?string} [parentFolderId=null] - The Google Drive ID of the parent folder.
* @param {boolean} [assignPermissions=false] - Whether to assign permissions to the folder.
* @returns {Promise<string>} A promise that, when resolved, returns the ID of the Google Drive folder.
*/
async findOrCreateFolder(folderName, parentFolderId = null, assignPermissions = false) {
try {
let query = `mimeType='application/vnd.google-apps.folder' and name='${folderName}' and trashed=false`;
if (parentFolderId) {
query += ` and '${parentFolderId}' in parents`;
}
// Search for the folder
let response = await this.drive.files.list({
q: query,
spaces: 'drive',
fields: 'files(id, name)',
});
const folder = response.data.files.length > 0 ? response.data.files[0] : null;
if (folder) { // The folder exists already
// Share the folder with the specified Google accounts
if (assignPermissions) {
const permissions = await this.drive.permissions.list({
fileId: folder.id,
fields: 'permissions(emailAddress, role)',
});
// Convert permissions into a map for easier access
const permissionsMap = new Map(permissions.data.permissions.map(p => [p.emailAddress, p.role]));
// Helper function to assign permissions if needed
const assignPermissionIfNeeded = async (email, role) => {
if (permissionsMap.get(email) !== role) { // Check if the user doesn't have the desired role
await this.shareFileWithUser(folder.id, email, role);
}
};
// Check and assign read permissions
for (const email of this.googleAccountsWithReadAccess) {
await assignPermissionIfNeeded(email, 'reader');
}
// Check and assign write permissions
for (const email of this.googleAccountsWithWriteAccess) {
await assignPermissionIfNeeded(email, 'writer');
}
}
return folder.id;
}
// Folder does not exist, so create it
const folderMetadata = {
name: folderName,
mimeType: 'application/vnd.google-apps.folder',
};
if (parentFolderId) {
folderMetadata.parents = [parentFolderId];
}
response = await this.drive.files.create({
resource: folderMetadata,
fields: 'id',
});
const folderId = response.data.id;
if (assignPermissions) {
for (const email of this.googleAccountsWithReadAccess) {
await this.shareFileWithUser(folderId, email, 'reader');
}
for (const email of this.googleAccountsWithWriteAccess) {
await this.shareFileWithUser(folderId, email, 'writer');
}
}
return folderId;
} catch (error) {
console.error(`Error finding or creating folder '${folderName}':`, error);
throw error;
}
}
/**
* Shares a Google Drive file with a specified user by granting them a specific access level.
*
* @param {string} fileId - The ID of the Google Drive file to share.
* @param {string} userEmail - The email address of the user with whom the file will be shared.
* @param {string} [accessLevel='reader'] - The level of access to grant to the user. Optional, defaults to 'reader' if not provided. Possible values include 'reader', 'writer', and 'commenter'.
* @throws {Error} Throws an error if sharing the file fails.
*/
async shareFileWithUser(fileId, userEmail, accessLevel = 'reader') {
const permissions = {
type: 'user',
role: accessLevel,
emailAddress: userEmail,
};
try {
await this.drive.permissions.create({
resource: permissions,
fileId: fileId,
fields: 'id',
});
} catch (error) {
console.error('Error sharing file:', error);
throw error;
}
}
}
// Export as a singleton
module.exports = GoogleDriveClient;
Step 9: The archiver script
Here is the script that actually finds the attachments, downloads them from Jira, uploads them to Google Drive and then replaces the attachments inside the issue description and comments with a clickable link to the Google Drive file.
require('dotenv').config();
const JiraClient = require('./jiraClient');
const GoogleDriveClient = require('./googleDriveClient');
const jiraDomain = process.env.JIRA_DOMAIN;
const jiraEmail = process.env.JIRA_EMAIL;
const jiraApiToken = process.env.JIRA_API_TOKEN;
const googleAccountsWithReadAccess = process.env.GOOGLE_ACCOUNTS_WITH_READ_ACCESS.split(',');
const googleAccountsWithWriteAccess = process.env.GOOGLE_ACCOUNTS_WITH_WRITE_ACCESS.split(',');
const googleDriveFolderName = process.env.GOOGLE_DRIVE_FOLDER_NAME;
const jira = new JiraClient(jiraDomain, jiraEmail, jiraApiToken);
const googleDriveClient = new GoogleDriveClient('./google-service-account-key.json', googleAccountsWithReadAccess, googleAccountsWithWriteAccess);
/**
* Processes all Jira projects by downloading attachments, uploading them to Google Drive,
* and updating Jira issues to link to the attachments' new locations on Google Drive.
*
* This function iterates through all projects retrieved from Jira, creates corresponding folders
* in Google Drive under a specified top-level folder, and processes each issue within the projects.
* For each issue, it downloads attachments, uploads them to Google Drive, and updates the issue's
* description and comments in Jira to replace references to the original attachments with links
* to the Google Drive versions. Standalone attachments not linked in descriptions or comments
* are also moved to Google Drive, and a comment is added to the issue with the new link before the
* attachment is deleted from Jira.
*
* @returns {Promise<void>} A promise that resolves when all projects, issues, and attachments
* have been processed. Throws errors for any failed operations.
* @throws {Error} Throws an error if any step in the process fails, including folder creation,
* attachment download and upload, updating issue descriptions and comments,
* or deleting attachments from Jira.
*/
async function processJiraProjects() {
let topLevelFolderId = await googleDriveClient.findOrCreateFolder(googleDriveFolderName, null, true);
let projects = await jira.getAllProjects();
for (const project of projects) {
console.log("Processing project " + project.name + " - " + project.key);
const projectFolderId = await googleDriveClient.findOrCreateFolder(project.name, topLevelFolderId, true);
const issues = await jira.getAllIssuesInProject(project.id, true, 100, true);
for (const issue of issues) {
let issueDetails = await jira.getIssueDetails(issue.id);
console.log("Processing issue " + issue.key + " which has " + issueDetails.fields.attachment.length + " attachments.");
const description = issueDetails.fields.description;
for (const attachment of issueDetails.fields.attachment) {
let { attachmentFileId, attachmentFileName, googleDriveAttachmentUrl } = await downloadAttachmentFromJiraAndUploadToGoogleDrive(issue, attachment, projectFolderId);
// Replace the attachment in the description
if (description && description.content) {
let updatedContent = getUpdatedADFContent(description.content, attachmentFileId, attachmentFileName, googleDriveAttachmentUrl);
let updatedAdfBody = {
type: 'doc',
version: 1,
content: updatedContent
};
await jira.updateIssueDescription(issue.id, updatedAdfBody);
description.content = updatedContent;
}
// Replace the attachment in all the comments
const comments = issueDetails.fields.comment.comments;
for (const comment of comments) {
let updatedAdfContent = getUpdatedADFContent(comment.body.content, attachmentFileId, attachmentFileName, googleDriveAttachmentUrl);
let updatedAdfBody = {
type: 'doc',
version: 1,
content: updatedAdfContent
};
await jira.updateComment(issue.id, comment.id, updatedAdfBody);
comment.body.content = updatedAdfContent;
}
// All attachments in the description and comments have been replaced with Google Drive links.
// Jira automatically removes them from the attachments list when no description or comment links to them.
// Any attachments that still remain in the attachments list are standalone attachments.
// We already downloaded them in the previous step. Now we need to create a new comment with the Google Drive link. Then delete them.
// Find the remaining attachments that still exist
updatedIssueDetails = await jira.getIssueDetails(issue.id);
for (const remainingAttachment of updatedIssueDetails.fields.attachment) {
if (remainingAttachment.id === attachment.id) { // The attacment that we are processing is still in the attachments list
const adfComment = {
type: "doc",
version: 1,
content: [
{
type: "paragraph",
content: [
{
type: "text",
text: `Attachment ${remainingAttachment.filename} was moved to Google Drive: `
},
{
type: "text",
text: remainingAttachment.filename,
marks: [
{
type: "link",
attrs: {
href: googleDriveAttachmentUrl,
title: remainingAttachment.filename
}
}
]
},
{
type: "text",
text: " ."
}
]
}
]
};
await jira.createAdfComment(issue.id, adfComment);
console.log("Deleting standalone attachment " + remainingAttachment.filename);
await jira.deleteAttachment(attachment.id);
}
}
}
}
}
}
/**
* Downloads an attachment from Jira and uploads it to Google Drive.
* Then returns information about the uploaded file.
*
* @param {Object} issue - The Jira issue object containing details like the issue key.
* @param {Object} attachment - The attachment object from Jira, including the filename and other metadata.
* @param {string} projectFolderId - The ID of the Google Drive folder associated with the project,
* where the issue's folder will be created or found.
* @returns {Promise<Object>} A promise that resolves with an object containing the original attachment's
* file ID from Jira (`attachmentFileId`), the filename of the attachment
* (`attachmentFileName`), and the URL to the uploaded file on Google Drive
* (`googleDriveAttachmentUrl`).
* @throws {Error} Throws an error if any step in the process (folder creation, file download, file upload) fails.
*/
async function downloadAttachmentFromJiraAndUploadToGoogleDrive(issue, attachment, projectFolderId) {
// Get the Google Drive folder ID for this issue
const issueFolderId = await googleDriveClient.findOrCreateFolder(issue.key, projectFolderId);
issueFolderUrl = `https://drive.google.com/drive/folders/${issueFolderId}`;
// Download attachment from Jira
let { attachmentFileId, filePath } = await jira.downloadAttachment(attachment);
// Upload attachment to Google Drive
const googleDriveFileId = await googleDriveClient.uploadFile(issueFolderId, filePath);
// Construct the Google Drive file URL
const attachmentFileName = attachment.filename; // The filename of the attachment
const googleDriveAttachmentUrl = `https://drive.google.com/file/d/${googleDriveFileId}/view`;
return {
attachmentFileId: attachmentFileId,
attachmentFileName: attachmentFileName,
googleDriveAttachmentUrl: googleDriveAttachmentUrl
}
}
/**
* Updates Atlassian Document Format (ADF) content by replacing references to a specific attachment
* with a hyperlink to the attachment's new location on Google Drive.
*
* This function iterates over the top-level nodes of the provided ADF content. For each node, it
* invokes a recursive function to search for and replace references to the specified attachment
* with a link to the attachment's new location. The replacement is based on matching the attachment's
* file ID within the ADF structure.
*
* @param {Object[]} adfContent - An array of ADF nodes representing the content of a Jira issue
* description or comment.
* @param {string} attachmentFileId - The file ID of the attachment to be replaced within the ADF content.
* @param {string} attachmentFileName - The name of the attachment, used as the link text in the
* replaced hyperlink.
* @param {string} googleDriveAttachmentUrl - The URL to the attachment's new location on Google Drive,
* used as the href in the replaced hyperlink.
* @returns {Object[]} The modified array of ADF nodes with the specified attachment references replaced
* by hyperlinks to Google Drive.
*/
function getUpdatedADFContent(adfContent, attachmentFileId, attachmentFileName, googleDriveAttachmentUrl) {
// Apply the recursive function to each top-level node in the ADF structure
let updatedContent = adfContent.map(node => jira.replaceAttachmentInADF(node, attachmentFileId, attachmentFileName, googleDriveAttachmentUrl));
return updatedContent;
}
processJiraProjects();
To run the script you do this:
$ node src/index.js
This can be scheduled with a cron.
Conclusion
We’ve shared a functioning script that processes all of your Jira projects and archives their attachments to Google Drive. If you are interested in using this script but need help setting it up, or you have more complex requirements, please reach out to us for a consultation.